SPARK job 성능에 중요한 영향을 미치는 설정 값들에 대해 정리한다.
1. 용어정리
하나의 Spark executor = 하나의 YARN container 라고 보면된다.
그리고 하나의 task = 하나의 core = 하나의 vcore 다.
하나의 executor가 여러개의 task를 동시에(concurrent) 부릴 수 있다.
Driver : 중앙 조정자
Executor : 분산 작업 노드
드라이버와 익스큐터는 각각 독립된 자바 프로세스
1. 드라이버
사용자의 main 메소드가 실행되는 프로세스

• 주요 역할
사용자 프로그램을 태스크로 변환하여 클러스터로 전송
1. 연산들의 관계를 DAG(Directed Acyclic Graph) 생성
2. DAG를 물리적인 실행 계획으로 변환
•최적화를 거쳐 여러 개의 stage로 변환
•각 stage 는 여러개의 태스크로 구성
3. 단위 작업들을 묶어서 클러스터로 전송
• 익스큐터에서 태스크들의 스케쥴링
• 익스큐터들은 시작시 드라이버에 등록됨
• 드라이버는 항상 실행중인 익스큐터를 감시
• 태스크를 데이터 위치에 기반해 적절한 위치에서 실행이 되도록 함
• 4040 포트를 사용하여 웹 인터페이스로 실행 정보를 볼수 있음
2. 익스큐터
개별 태스크를 실행하는 작업 실행 프로세스

• 주요 역할
태스크 실행 후 결과를 드라이버로 전송
• 사용자 프로그램에서 캐시하는 RDD를 저장하기 위한 메모리 공간 제공
3. 노드 매니저
스파크는 익스큐터를 싱행하기 위해 클러스터 매니저에 의존

프로그램이 실행되는 단계
- 사용자가 spark-submit을 사용해 애플리케이션 제출
- spark-submit은 드라이버 프로그램을 실행하여 main 메소드 호출
- 드라이버는 클러스터 매니저에서 익스큐터 실행을 위한 리소스 요청
- 클러스터 매니저는 익스큐터를 실행
- 드라이버는 태스크 단위로 나누어 익스큐터에 전송
- 익스큐터는 태스크를 실행 7. 애플리케이션이 종료되면 클러스터 매니저에게 리소스 반납
- executor에 대한 설정 (--num-executors = spark.executor.instances)
num-executors 와 spark.executor.instances 는 서로 같은 의미이다.
전자는 spark-shell이나 spark-submit 으로 명령을 날릴 때 넣어주는 방식이고, 후자는 spark-defaults.conf 파일에 적어둘 때의 설정 이름이다.
spark-shell이나 spark-submit 으로 명령을 날릴 때, 아래와 같이 적어도 같은 뜻이 된다.
--conf spark.executor.instances=
따라서 아래 두 설정은 동일한 의미이다.
--conf spark.executor.instances=32
--num-executors 32
- task에 대한 설정 (--executor-cores = spark.executor.cores)
각 executor가 사용하는 thread의 수라고 볼 수 있다.
rough하지만 경험적으로 한 executor당 5 보다 작게 설정 할 때,
가장 성능이 좋다고 한다.
※ 참고 => http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
너무 많으면 context switching 등이나 HDFS I/O 때문에 성능이 떨어지고,
너무 적으면 하나의 JVM을 공유하는 장점이 사라진다.
예를 들어, spark에서 어떤 데이터를 broadcast 했을 때 동일한 JVM (= 동일한 executor)의 task들이 해당 데이터를 공유하게 된다.
만약 --executor-cores 1로 설정해서 한 executor가 하나의 task만 실행하게 하면, 위와 같은 장점을 잃는다.
더 수가 많고 작은 executor 들이 똑같은 데이터의 사본을 갖게 되는 것이다.
아래 처럼 설정할 수 있다.
--conf spark.executor.cores=5
혹은
--executor-cores 5
spark job을 실행시킬 때 우리가 컨트롤 할 수 있는 설정은 크게 CPU와 메모리 두 가지이다.
그 외 요인들, 이를테면 네트워크 I/O나 Disk 등의 성능은 Spark나 YARN에게 요청할 수 없기 때문이다.
- CPU에 관련된 설정
위에 설명한 executor와 task 설정을 우리가 가진 서버(Nodes) 와 CPU 개수메 맞추어 설정해야 한다.
따라서,
(executor 수) X (task 수) < (node 수) X (각 node의 CPU 개수)
이어야 한다.
하지만 이것만으로 최적이라볼 수는 없는데, 그 이유는 아래 2번에서 설명하겠다.
<= 아니라 < 인 이유는 시스템 자체적으로 OS나 NodeManager등을 위해서 idle한 CPU를 남겨두자는 것이다.
- 메모리에 관련된 설정 (--executor-memory = spark.executor.memory)
Spark와 YARN의 메모리 관리 구조를 계층화해서 표현한 도식은 아래와 같다.
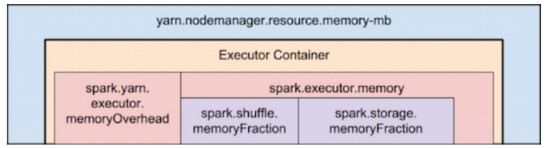
더 자세한 내용 => http://blog.naver.com/gyrbsdl18/220594197752 참고
결국 YARN이 어떻게 설정했느냐에 따라 제약을 당할 수 밖에 없다는 의미인데,
비록 그 제약 내이긴 하지만 우리의 Spark job 에서라도 최선을 다해보도록 하자.
우리가 할 수 있는 것은 executor의 메모리 설정이다. (task가 아님)
각 서버(node)가 가진 물리 메모리 수를 해당 서버가 책임질 것으로 예상되는 executor의 수로 나눈 값으로 설정하면 된다.
이 문장이 잘 이해가 안갈 수 있는데, executor라는 것은 RM (resource manager)가 관리하는 논리적인 단위이기 때문이다.
2번의 예제를 살펴보면 이해가 쉬울 것이다.
CPU와 마찬가지로, 시스템을 위한 물리 메모리 1GB 이상을 늘 남겨두어야 한다.
2. 물리 서버의 상태에 따라 설정 값들을 최적화 시키기
서론이 너무 길었으므로, 다짜고짜 쉬운 예제를 통해 설명하겠다.
서버는 총 6대,
각 서버가 가진 CPU는 16개,
그리고 각 서버가 가진 메모리는 64GB
라고 하자.
아래를 읽기 전에 우선 '어떻게 설정 해볼까?' 고민해보자.
단순하게 생각하면 아래와 같은 설정을 떠올려 볼 수 있다.
BAD case:
--num-executors 6 --executor-cores 15 --executor-memory 63G
하지만 위와 같은 설정이 좋지 않은 이유는 아래와 같다.
1) 64GB 시스템에서 OS나 NodeMagager가 사용해야하는 메모리 여유분이 있어야 하기 때문에, 63GB까지 사용하는 것은 힘들다.
2) 한 executor에 15개의 core를 사용하면 HDFS I/O throughput이 낮아지는 등, 성능 저하를 유발할 수 있다. (위에서도 밝혔듯이 1보다는 크게, 그리고 5 보다는 작게 설정하는 것이 좋다)
3) AM은 각 서버당 1개의 executor만 배정하게 될 것이다. 각 서버가 16개의 core를 가지고 있고 idle로 1개를 뺀다고 해도 15개의 여유분이 있는데, 너무 적게 사용한 꼴이 된다.
따라서 이런 경우 더 적합한 설정은 다음과 같다.
GOOD case:
--num-executors 17 --executor-cores 5 --executor-memory 19G
1) 노드마다 대략 3개의 executor가 수행될 수 있고, 각 executor는 5개의 core(=task)를 갖게 된다.
17 * 5 = 85
는 전체 시스템 CPU개수인 6 * 15 = 90 보다 작다는 점을 기억하자.
2) --executor-memory 는 63.0 / 3 - 2 = 19 로 계산한 것이다.
※ 참고로 driver에 관한 core, memory 설정도 위와 비슷한 사고의 흐름을 따라 설정하면 되는데,
executor에 비해 마이너한 주제이기도 하고, yarn-client 인지 yarn-cluster인지에 따라 node가 달라지기 때문에 설명하지 않았다.
설정 값은 다음 두 개이며,
spark.driver.cores (--driver-cores)
spark.driver.memory (--driver-memory)
만약 설정하지 않으면 Spark는 default로 1 core, 1GB 로 설정된다.